Big Data
No Bullshit
Retour d'expérience
Dictanova et Cityzen Data
Par Damien Raude-Morvan et David Morin
Présentation au Nantes Java User Group - 15 décembre 2014
Agenda
- Présentation des speakers (5 min)
Damien, David - Dictanova (15 min)
TALN, BigData - Cityzen Data (15 min)
IoT, BigData - Présentation de nos problématiques (80 min)
Speakers
Damien Raude-Morvan

- Responsable technique de Dictanova
-
 @drazzib
/
@drazzib
/
 draudemorvan
/ CV
draudemorvan
/ CV - Open Source
- Développeur Debian
- Commiter et PMC Apache Gora
- +++
- Enseignant vacataire à l'Université de Nantes
David Morin

- Ingénieur Solutions chez Cityzen Data
-
@davAtBzh
/
david-morin
- Open Source
- Développeur avant tout - Touche à tout
- En ce moment : Ambrose pour Pig et Elephant-bird
- ...
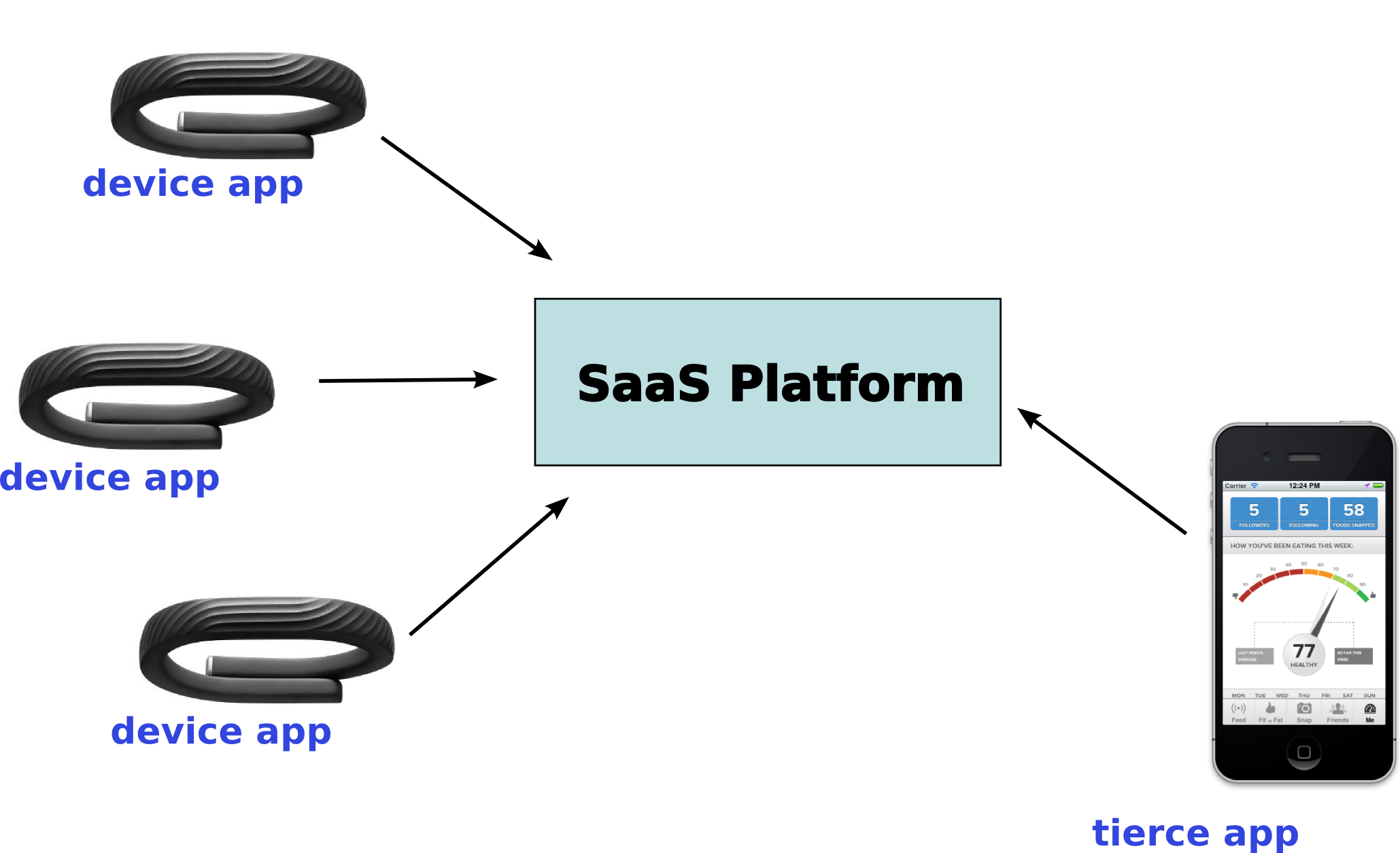
The Customer Voice Platform
intermédiaire entre
les prises de parole consommateur
et les marques
The Customer Voice Platform
-
 Que disent les internautes de ma marque ?
Que disent les internautes de ma marque ?
-
 Comment en parlent-ils ?
Comment en parlent-ils ?
-
 Avec quel degré d'implication ?
Avec quel degré d'implication ?
-
 Où en parlent-ils ?
Où en parlent-ils ?
-
 Quelles sont les prises de paroles les plus représentatives ?
Quelles sont les prises de paroles les plus représentatives ?
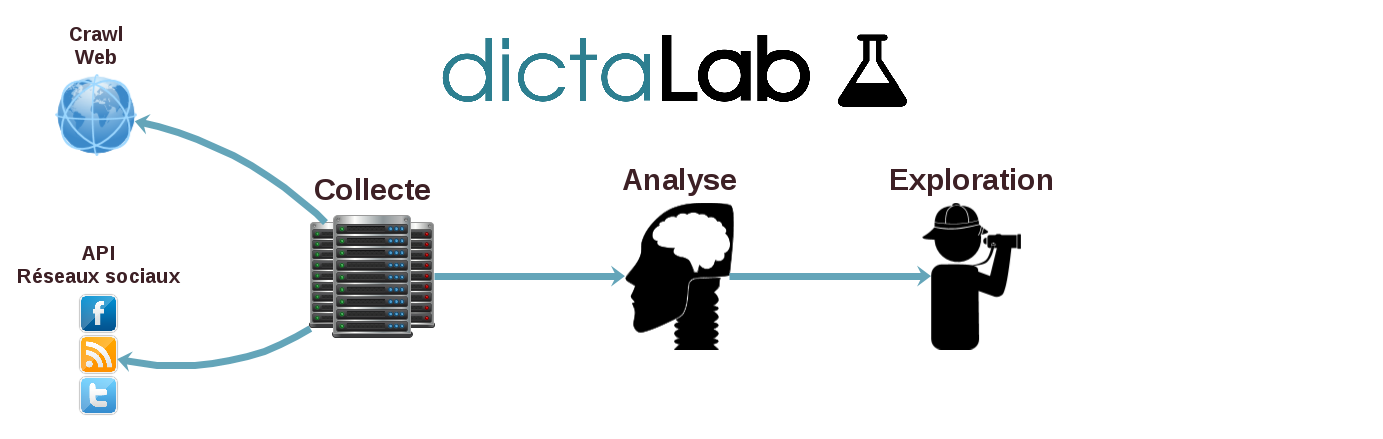
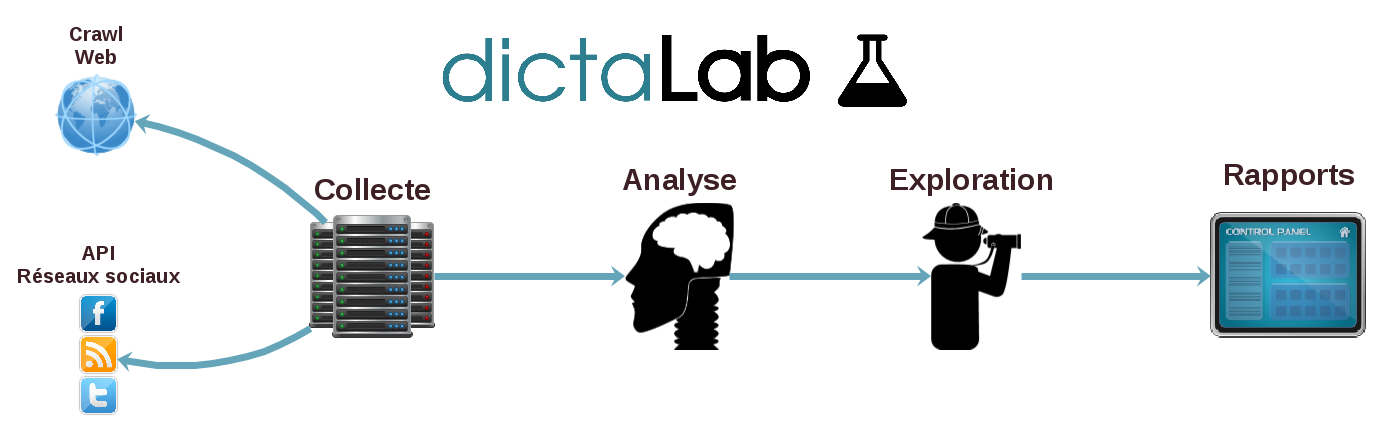
Savoir faire
- Collecter des masses de données textuelles (web, emails, chats etc.)
- Structurer des données textuelles (opinions, thématiques, entités nommées, etc.)
- Explorer les résultats (recherche avec facette, rapports, alertes)
Quelles technologies ?
Architecture

Powered By...
Collecte




Analyse TALN
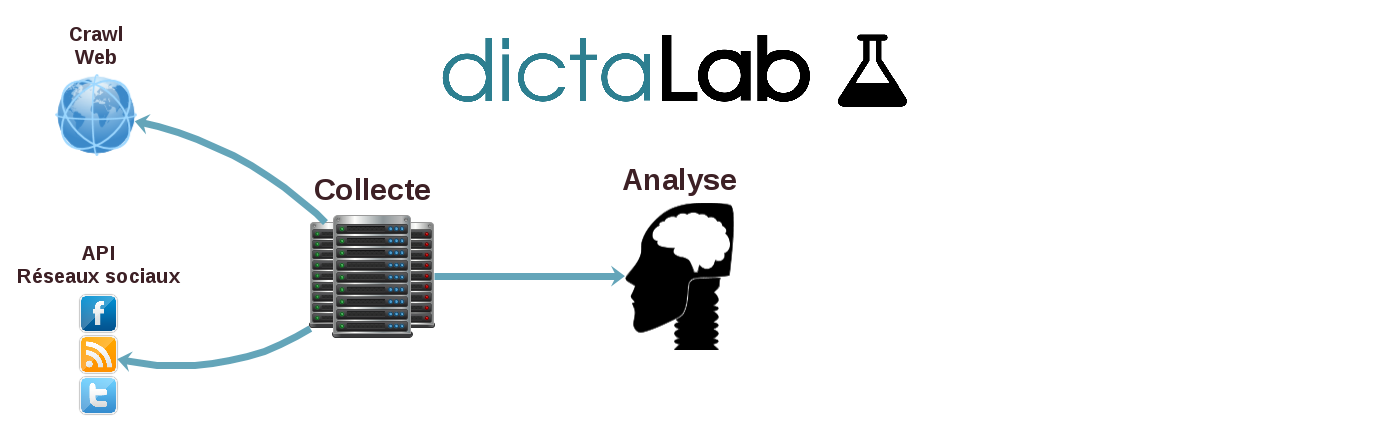

Exploration
Dashboard













Retour d'expériences
Infrastructure Hadoop

Daemons ?

Help !!
- Hadoop Native : libhadoop.so + libhdfs.so + protoc
- Processus fail-fast : besoin de monitoring avec SupervisorD
- Interface d'administration du cluster ?
Comment éviter ce temps de mise en oeuvre et de maintenance important ?
Hadoop-as-a-Service
OVH Dedicated Hadoop As a Service
- Distribution CDH 5 (Cloudera)
- Encore en béta privée pour l'instant
- Un rapport coût par CPU / par IOPS très intéressant versus le Cloud
Limites
- Difficulté à obtenir des performances en terme d'IO sur le Cloud
- Des offres pas toujours très flexibles en terme de paramètrage
- Complexe voir impossible d'installer des composants natifs
Dictanova: nos expérimentations à venir
- CloudBreak : Docker + Apache Ambari
- Évalutation de la grille de tarif d'OVH Dedicated Hadoop-as-a-Service
Format des données
Fichiers de logs
Je vais importer directement mes fichiers de logs dans HDFS !
2014-12-13 14:17:48 RelevanceFilter [INFO] Verbatim result: relevant scored, emitted
2014-12-13 14:19:34 RelevanceFilter [INFO] Verbatim result: relevant scored, emitted
2014-12-13 14:27:30 RelevanceFilter [INFO] Verbatim result: relevant scored, emitted
2014-12-13 14:28:07 RelevanceFilter [INFO] Verbatim result: relevant scored, emitted
- Des expressions régulières pour l'extraction
- Mapping vers un POJO
Changement de format de log ?
2014-12-13T14:17:48 d.a.r.RelevanceFilter [INFO] Verbatim result: relevant scored, emitted, (key=verbatim://mission/54631a440cf2118b4f346d6e/1e482ca4d4f3aa00e0745e409903b142, relevance=1.0)
2014-12-13T14:19:34 d.a.r.RelevanceFilter [INFO] Verbatim result: relevant scored, emitted, (key=verbatim://mission/54631a440cf2118b4f346d6e/1e482caa1f2ba500e0743d4617c85ffa, relevance=1.0)
2014-12-13T14:27:30 d.a.r.RelevanceFilter [INFO] Verbatim result: relevant scored, emitted, (key=verbatim://mission/546369e20cf2118b4f3d8266/1e482cbbc795ae00e0745c0a84ceaea8, relevance=1.0)
2014-12-13T14:28:07 d.a.r.RelevanceFilter [INFO] Verbatim result: relevant scored, emitted, (key=verbatim://mission/54631a440cf2118b4f346d6e/1e482cbd9159a600e074660bbb69ef8e, relevance=1.0)
- Changement du format de date (ISO 8601)
- Package de la classe
- Informations contextuelles (MDC)
Comment stocker mes données sans avoir peur des évolutions ?
Apache Thrift
- Compilateur thrift : génère la partie données (POJO) et la couche RPC (client et service)
- Multi langages : C, C++, Java, OCaml, Perl, PHP, Python, Ruby, Javascript, Go, etc...
- Interface Definition Language : syntaxe simple - On va à l'essentiel
namespace java com.example.project
enum TweetType {
TWEET,
RETWEET = 2,
DM = 0xa,
REPLY
}
struct Tweet {
1: i32 userId,
2: string userName,
3: string text,
4: TweetType tweetType = TweetType.TWEET
}
Apache Thrift
- Transport : TCP par défaut (surcouche HTTP posible)
- Protocol : protocole de sérialisation (TBinaryProtocol, TCompactProtocol, etc...)

Apache Thrift
- Point essentiel : compatibilité ascendante et descendante
namespace java com.example.project
enum TweetType {
TWEET,
RETWEET = 2,
DM = 0xa,
REPLY
}
struct Tweet {
1: i32 userId,
2: string userName,
3: string text,
4: TweetType tweetType = TweetType.TWEET,
// Add Location !
5: Location location
}
Apache Gora

Apache Gora
Deux niveaux :
- Modèle de données in-memory via Apache Avro
- DataStore pour la persistence vers du NoSQL
Apache Gora : fonctionnalités
- Persistence : vers des bases colonnes, clef-valeur, document, des fichiers dans HDFS ou encore du SQL
- API : Accès homogène aux données peu importe la source
- Indexation : stockage des données dans Lucene/SOLR et requêtage avec l'API Gora
- Hadoop Map/Reduce : lancement simplifier d'un Job MR (Input/Output formats)
Apache Gora : Datastore
| clé-valeur | orientée colonnes | orientée documents | autre |
|---|---|---|---|

|



|

|
JDBC |
Apache Gora : How-To
- Définir son schéma avec Avro
{ "type": "record", "name": "Pageview", "namespace": "org.apache.gora.tutorial.log.generated", "fields": [ {"name": "url", "type": "string"}, {"name": "timestamp", "type": "long"}, {"name": "ip", "type": "string"}, {"name": "httpMethod", "type": "string"}, {"name": "httpStatusCode", "type": "int"}, {"name": "responseSize", "type": "int"}, {"name": "referrer", "type": "string"}, {"name": "userAgent","type": "string"} ] } - Compiler le schema => génération de code
bin/gora goracompiler gora-tutorial/src/main/avro/pageview.json target/generated-sources/
Apache Gora : How-To
- Création d'un mapping logique vers physique : Object-to-Datastore Mapping
- Fichier gora.properties pour définir les paramètres de stockage
gora.datastore.default=org.apache.gora.hbase.store.HBaseStore gora.datastore.autocreateschema=true gora.datastore.scanner.caching=1000 hbase.client.autoflush.default=false
Apache Gora : Map/reduce
Consommer ces données dans un job MR ?
inStore = DataStoreFactory.
getDataStore(dataStoreClass, Long.class, Pageview.class, conf);
outStore = DataStoreFactory.
getDataStore(String.class, MetricDatum.class, conf);
Job job = new Job(getConf());
job.setJobName("Log Analytics");
job.setNumReduceTasks(numReducer);
job.setJarByClass(getClass());
GoraMapper.initMapperJob(job, inStore,
TextLong.class, LongWritable.class, XXXXMapper.class, true);
GoraReducer.initReducerJob(job, outStore,
XXXXReducer.class);
Gora: chez Dictanova
- Format de sérialization de nos messages AMQP (Avro FTW!)
- Outil de stockage de nos données (~ 400 Go)
- Requêtage mixte MongoDB queries / Gora
Gora: évolutions dans les cartons
- Datastore pour ElasticSearch
- Interop. avec Hive & Pig
- Collaboration avec Apache Metamodel
Jobs => workflow de traitements
Apache Oozie
- Conçu pour l'orchestration de jobs sur Hadoop (MR, Pig, Hive, etc...)
- Exécution "à la crontab" ou comme un véritable ordonnanceur (dépendances, macro-jobs ou macro-tasks)
- Ok pour les traitements hors Hadoop : shell, java , etc...

Restons pragmatique
- Analyse de l'existant : de quoi je dispose comme ordonnanceur sur mon SI ?
- SSH est ton ami !
- Point essentiel : assurer la liaison entre l'ordonnanceur "historique" et les outils de supervision pour Hadoop
Exemple concret mis en oeuvre dans le passé : l'ordonnanceur "historique" fournit un fichier avec des variables d'environnement au script Pig permettant de contextualiser le Job MR sur le jobtracker (nom du Job initial, environnement, heure de lancement, user, etc...)
Analyse & requêtage
Apache Pig

Pourquoi un nouveau langage ?
Qu'est ce que ça m'apporte ?
Apache Pig

- Pig : modèle dataflow
- Script Pig => jobs MR + lancement sur le cluster Hadoop
- Facilité de prise en main du langage Pig Latin
- Extensible à l'infini : UDF (Java, Groovy, Javascript, Python, etc...)
- Libs d'UDFs complètes : PiggyBank (fournie avec Pig), Elephant-Bird (Twitter) et Apache DataFu (Linkedin)
- Engouement : projet Spork (Pig sur Spark) et Pig sur Tez (depuis 0.14)
Apache Pig - Word count
-- Load file on HDFS
-- Ex : ceci est un exemple de ligne pour le wordcount
lines = LOAD '/user/XXX/wc.txt' AS (line:chararray);
-- Iterate on each line
-- We use TOKENISE to split by word and FLATTEN to obtain a tuple
words = FOREACH lines GENERATE FLATTEN(TOKENIZE(line)) AS word;
-- Group by word
grouped = GROUP words BY word;
-- Count number of occurences for each group (word)
wordcount = FOREACH grouped GENERATE group, COUNT(words);
-- Display results on sysout
DUMP wordcount;

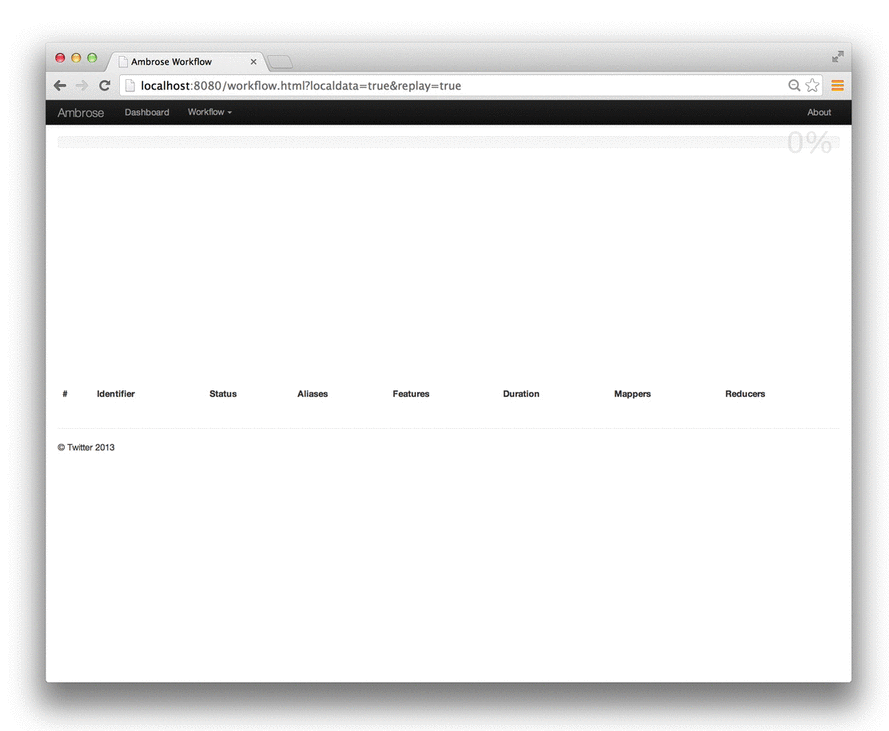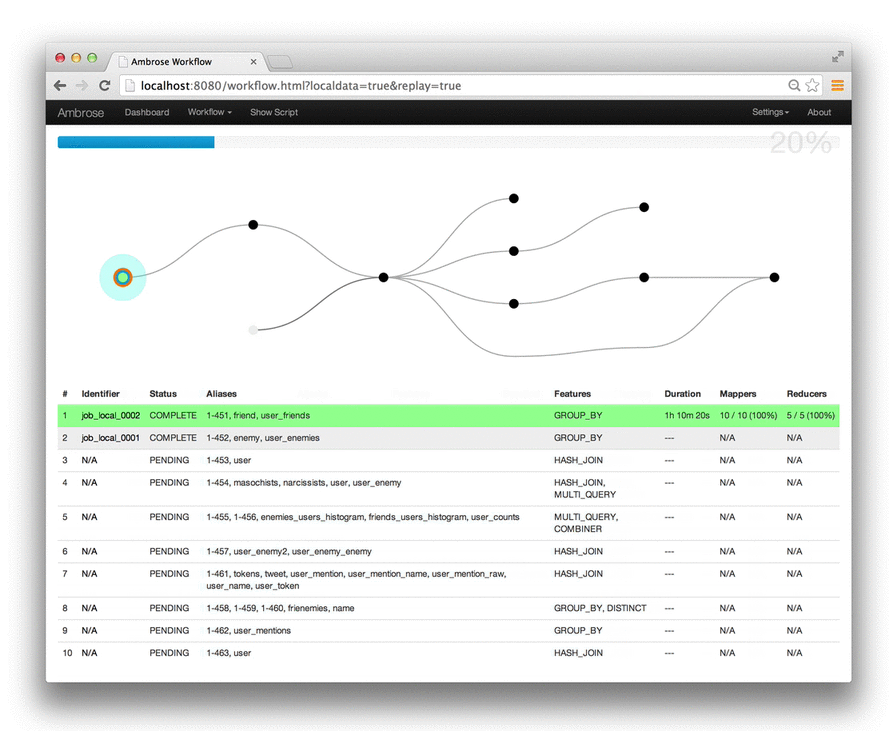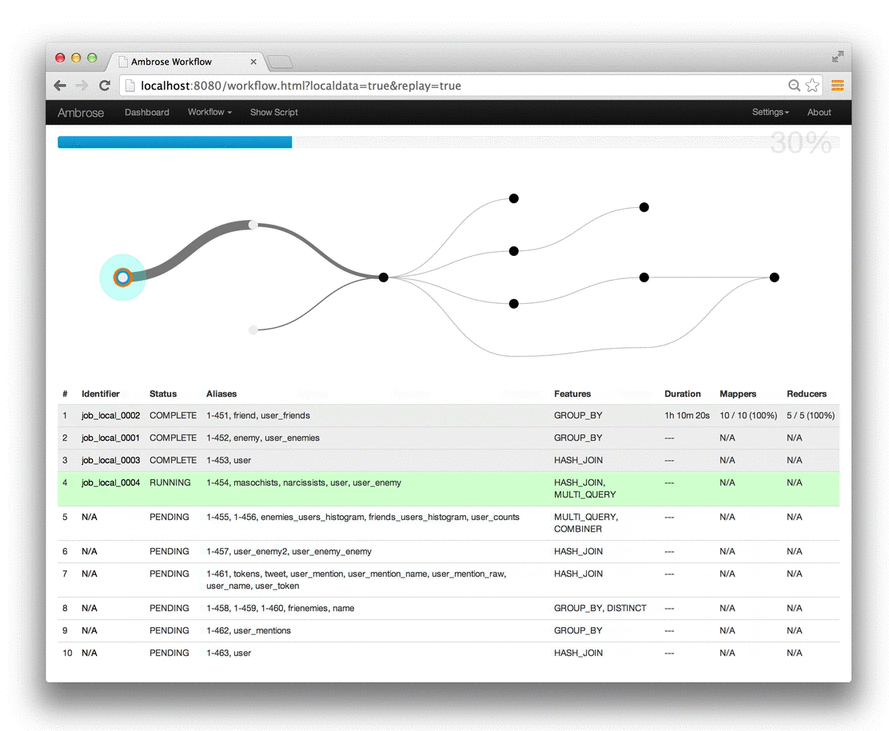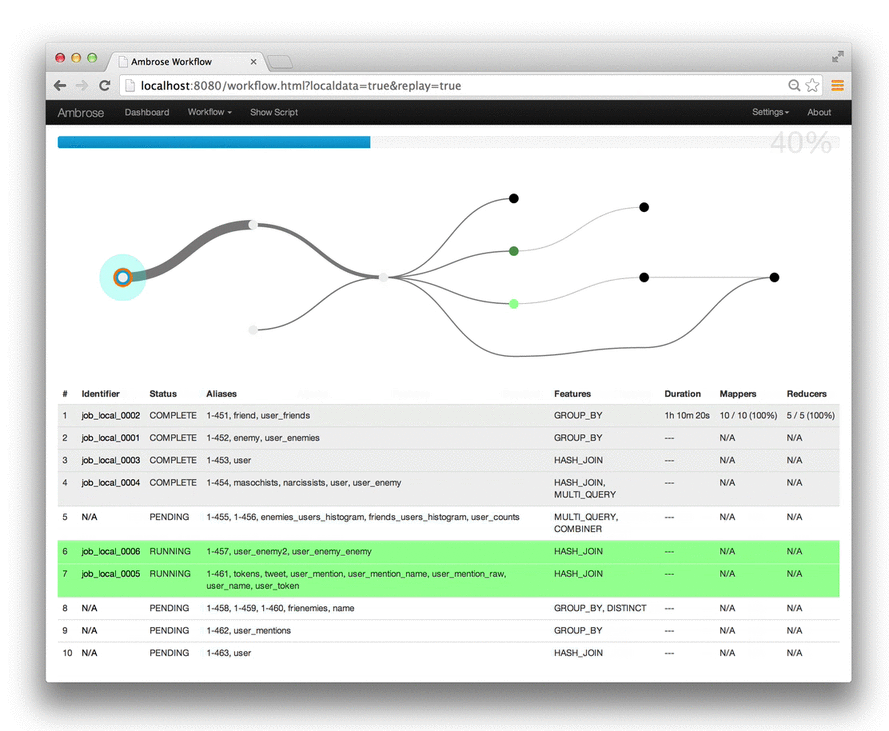
Comment analyser et suivre un script Pig en prod ?
- Possibilité de fournir des attributs au script Pig => attributs que l'on retrouve dans les Jobs MR
- Twitter/Ambrose : suivi en temps réel
Traitement de flux de données
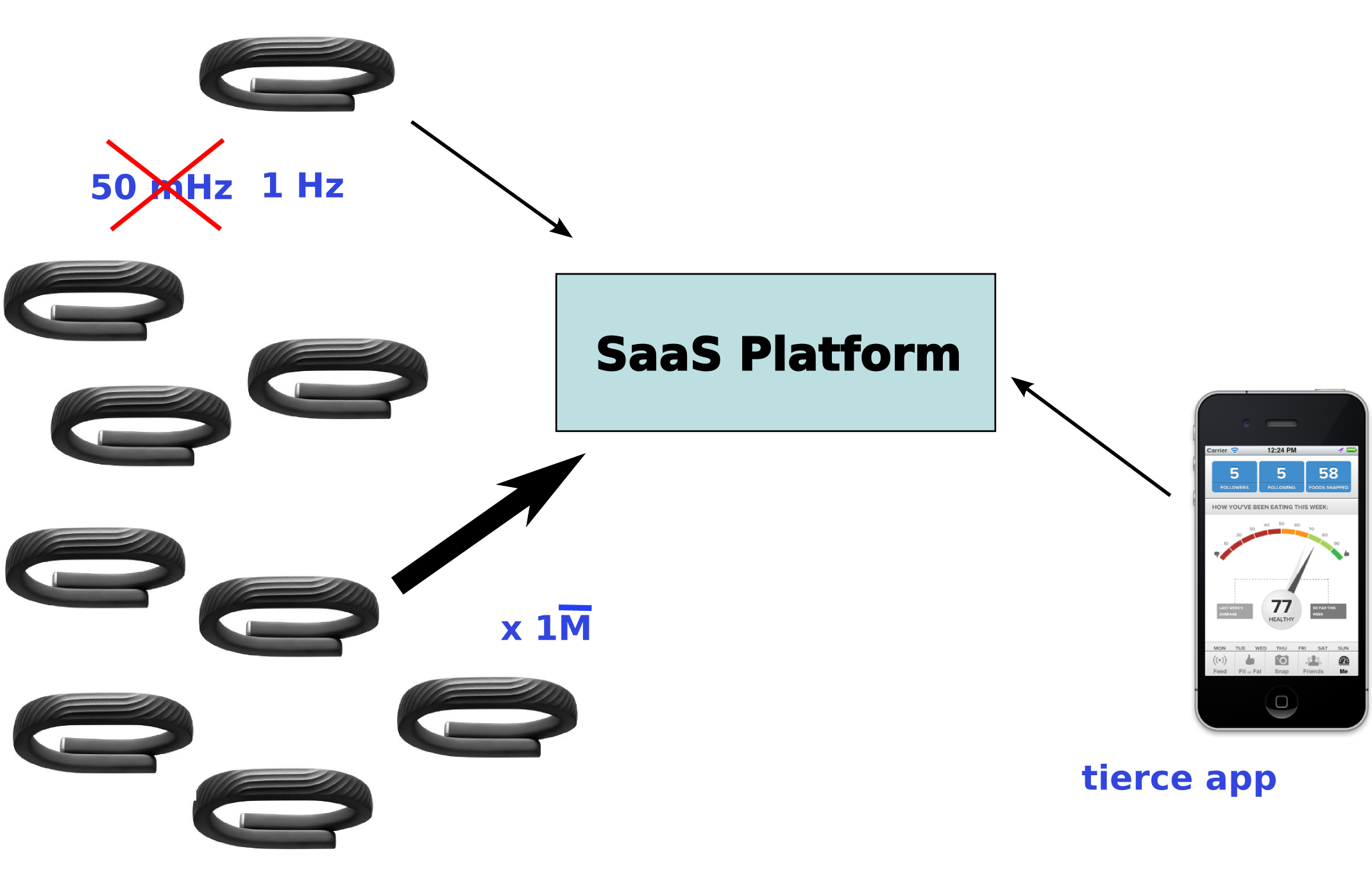
À l'échelle d'Internet, de plus en plus de données sont produites
Quelques types de flux
- Réseaux sociaux
Twitter / Facebook / Disqus
- Logs
applicatifs / techniques
- Actions des utilisateurs
clicks, achat, navigation
- Machine-2-Machine
capteurs
Traitement un flux de données
- Fastidieux
- Fragile
- Difficile à passer à l'échelle
Nos cas d'utilisations
- Traitement de flux : traiter un flux de données, tout en mettant à jour une base de données en temps réel
- RPC Distribué : paralléliser un calcul intensif, à la volée
Apache Storm : Spout
- Source externe pour un flux de données
RabbitMQ, Kafka, JMS
Apache Storm : Bolt
- Reçois un ou plusieurs flux de données
- Émet un ou plusieurs flux de données
- Implémente le traitement métier
Apache Storm : Stream
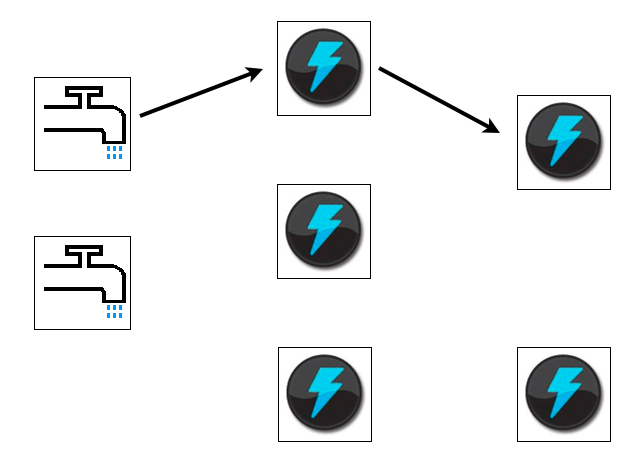
- Séquence illimitée de tuple
- Un stream peut être émit par un Bolt ou un Spout
Apache Storm : Topology
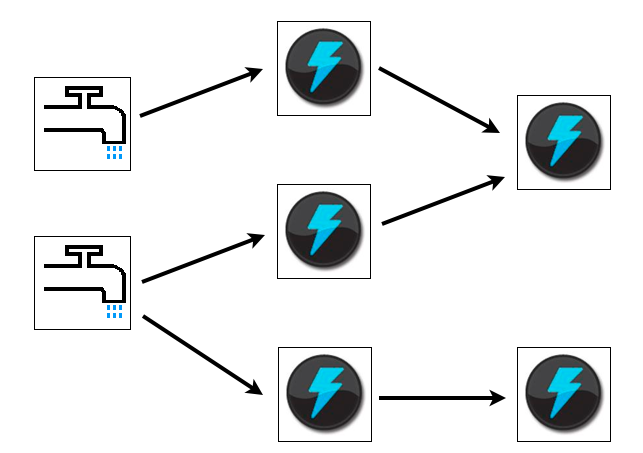
- Stream Grouping : description du regroupement des flux entre bolt
- Topology : DAG reliant des spout et des bolts via des regroupements de flux
Architecture logique
Nimbus
- Distribue le code de la topologie dans le cluster
- Assigne les taches aux différents workers
- Vérifie la bonne santé
Architecture logique
Zookeeper
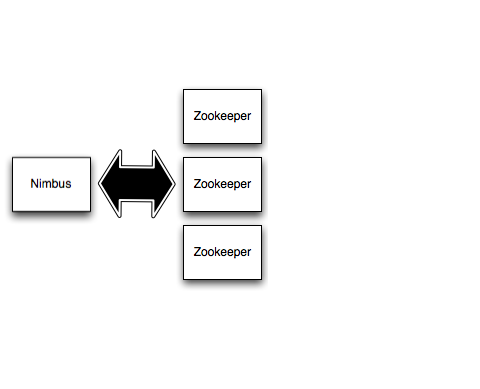
Stockage de l'état du cluster (répartition des travaux)
Architecture logique
Supervisor
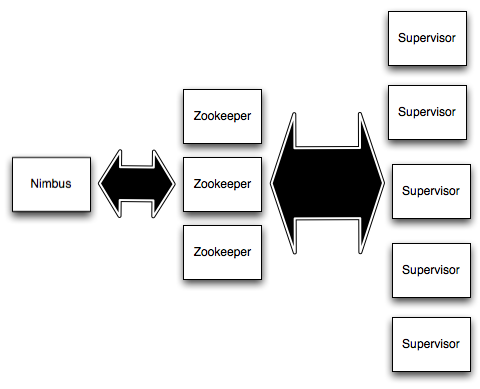
Démarre et stoppe les différents workers
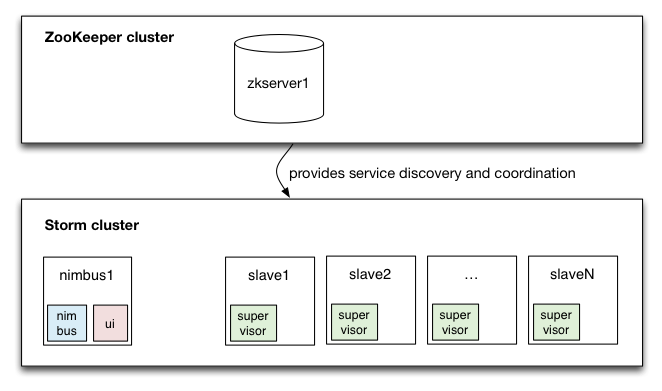
Architecture physique
Cluster Storm
Apache Storm - Trident
- Abstraction de plus haut niveau
- Transformation en primitives de l'API Storm
- Concepts :
- Grouping
- Filters
- Functions
- Aggregations
- Joins
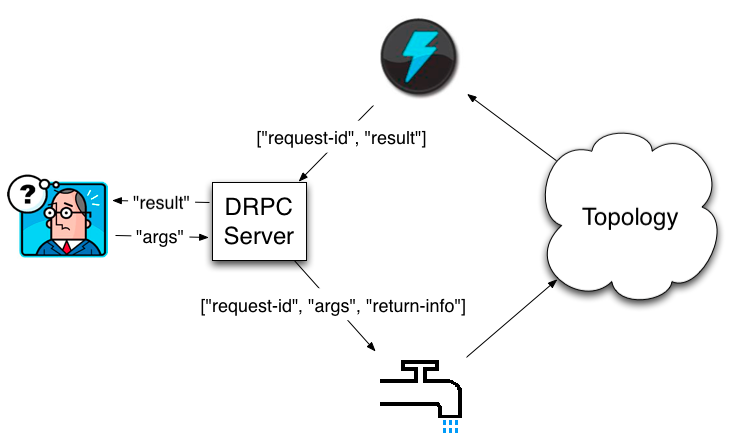
Apache Storm - DRPC 1/2
- Coordination d'une requête "RPC" dans le cluster Storm
- Transparent pour le client
- Permet de soumettre des requêtes ad-hoc
Apache Storm - DRPC 2/2